 Home
HomeName Matching Model for Entity Resolution (Part 1)

This is Part I of a two-part series; for Part II, click here.
Accurately determining whether two names refer to the same real-world entity is a real challenge in many enterprise information systems. This is acutely true in financial services, where financial institutions have to screen millions of transactions and compliance teams have to navigate complex customer records. Name matching thus sits at the heart of critical workflows such as entity resolution, anti-money-laundering (AML) monitoring, fraud detection, and KYC/onboarding checks. Yet, real-world names are often messy: They vary across languages, cultures, spellings, abbreviations, and data-entry conventions. Rule-based systems typically underperform in the face of this diversity, leading to high false-negative rates and missed risks. This is because linguistic nuances in names across languages simply can’t be completely coded in rules – think of Bob as diminutive for Robert, Bill for William or Sasha for Alexander (in Slavic languages).
This post introduces the Name Matching machine learning (ML) model and Python package that I have developed to address this problem. It provides a unified framework for comparing person and/or organization names and determining whether they represent the same entity – i.e., entity resolution. The package combines multiple linguistic signals and NLP features to deliver accurate and scalable name similarity scoring that can be applied to practical use cases, such as:
- Entity resolution – Consolidating fragmented customer records, deduplicating databases, and improving data quality across systems and workflows. For a primer on entity resolution and its applications, refer to this blog post.
- Transaction monitoring & AML – Matching counterparties and beneficiaries against sanctions and PEP lists with better recall (fewer false negatives).
- Fraud detection – Identifying suspicious patterns and hidden relationships such as slight name variations and mule account networks in transactions.
By offering a clean and modular API, the package further enables developers to adopt and integrate this solution into their applications with ease. The package is fully open-source under MIT license. The figure below illustrates the high-level data flow & training pipeline of the package.

The following sections elaborate on the components of the pipeline above (from left to right).
Synthetic data generation
Because Name Matching is an ML model, it has to be trained from some data – and because its main job is to match a pair of (person/organization) names and determine if they are the same entity or not, the training data can be synthesized from some name generation software. For this purpose, I use the Faker package to generate a set of “seed” names in a variety of Western (English, French, German, Italian, Spanish, Portuguese) and Asian (mostly Chinese and Japanese) languages. For better diversity, I have also added Arabic names to the training name pool. For this purpose, I make use of the ArabicNames package for synthetic Arabic name generation.
Both person and organization names can be generated in this manner. For organization names, only Western names are possible using Faker. All generated names (persons and organizations) are then combined together into a training set where training examples are derived.
In order to train an ML model, we need training examples. In this case, they are pairs of names that are considered “matched” (positive examples) and those that are “not matched” (negative examples). In this application, positive examples can be considered as aliases since they are typically common variations of the same name. Thus, in order to generate positive aliases, I make use of LLMs with proper prompting and comprehensive examples. I specifically designed separate prompts for person names and organization names to prompt the LLM for alias generation. The power of LLM here is its superb understanding of nuances in languages of different origins.
Examples of positive aliases of a hypothetical person’s name Joseph Azevedo are: Joe Azevedo (diminutive of first name), Azevedo Joseph (shuffle of first and last name), Joey Azevedo (another diminutive of first name) and Joseph Azeveda (misspelling of last name).
Examples of positive aliases of a hypothetical organization’s name Capricorn Asset Management LLC are: Capricorn Asset, Capricorn Asset Management, Capricorn Asset Mgmt and Capricorn Asset Management Limited Liability Company.
For negative example generation (a.k.a. negative sampling), I try to generate “hard” examples by generating pairs of names that are non-matching and confusing enough. The rationale is to train well the model with non-obvious examples where the names aren’t matched and yet “similar” in some sense, which is closer to realistic misclassification errors. To this end, for each name, I try to sample n negative samples from other names in the training set with the same first or last name (for person entities) and those with the closest edit distance to the original name (for both person and organization entities). This can be done algorithmically without prompting LLMs.
Examples of negative examples of a hypothetical person’s name Joseph Azevedo are: Joseph Fuentes (same first name), James Azevedo (same last name), Joshua Coleman and Jovan Pareja (sorted by edit distance).
Examples of negative examples of a hypothetical organization’s name Grupo Losa S.A. are: Campos S/A, Pinto Lda., Cousin Conrad SA and Polla Monnet SA.
This file contains the initial seed names. Pairs of positive aliases can be found in this file and pairs of negative examples can be found here.
Feature engineering
In order to train the model, pairs of names, whether positive or negative, have to be transformed into numerical features. This is because machine learning only works with numbers, and not with strings (or any other data types). This is called feature engineering. Let name_x and name_y denote a pair of names, the table below lists all the features derived to train the model.
| Feature Name | Description |
|---|---|
| Jaccard similarity | Intersection over union between tokens of name_x and name_y |
| TF-IDF cosine similarity | Cosine similarity between TF-IDF vectors of name_x and name_y |
| Ratio feature | Normalized edit distance between name_x and name_y |
| Sorted token ratio | Edit distance on sorted tokens of name_x and name_y |
| Token set ratio | Edit distance on unique sorted tokens of name_x and name_y |
| Partial ratio | Fuzzy string matching implemented by FuzzyWuzzy |
| Embedding distance | Cosine similarity between embedding vectors of name_x and name_y |
| String length difference | Difference between string lengths of name_x and name_y |
Raw string names are first “standardized” before being turned into features: Upper-cased, removed non-ASCII characters, numbers and punctuations to become name_x and name_y. Of the features listed above, Partial ratio relies on the package FuzzyWuzzy and Embedding distance relies on Sentence Transformers (a pre-trained embedding model) to compute the embedding vectors of 2 name strings. The latter is able to capture semantic nuances in names across languages (such as diminutives). The rest of the other features largely make use of the concept of edit distance to compare string similarities between name_x and name_y.
Model training & eval
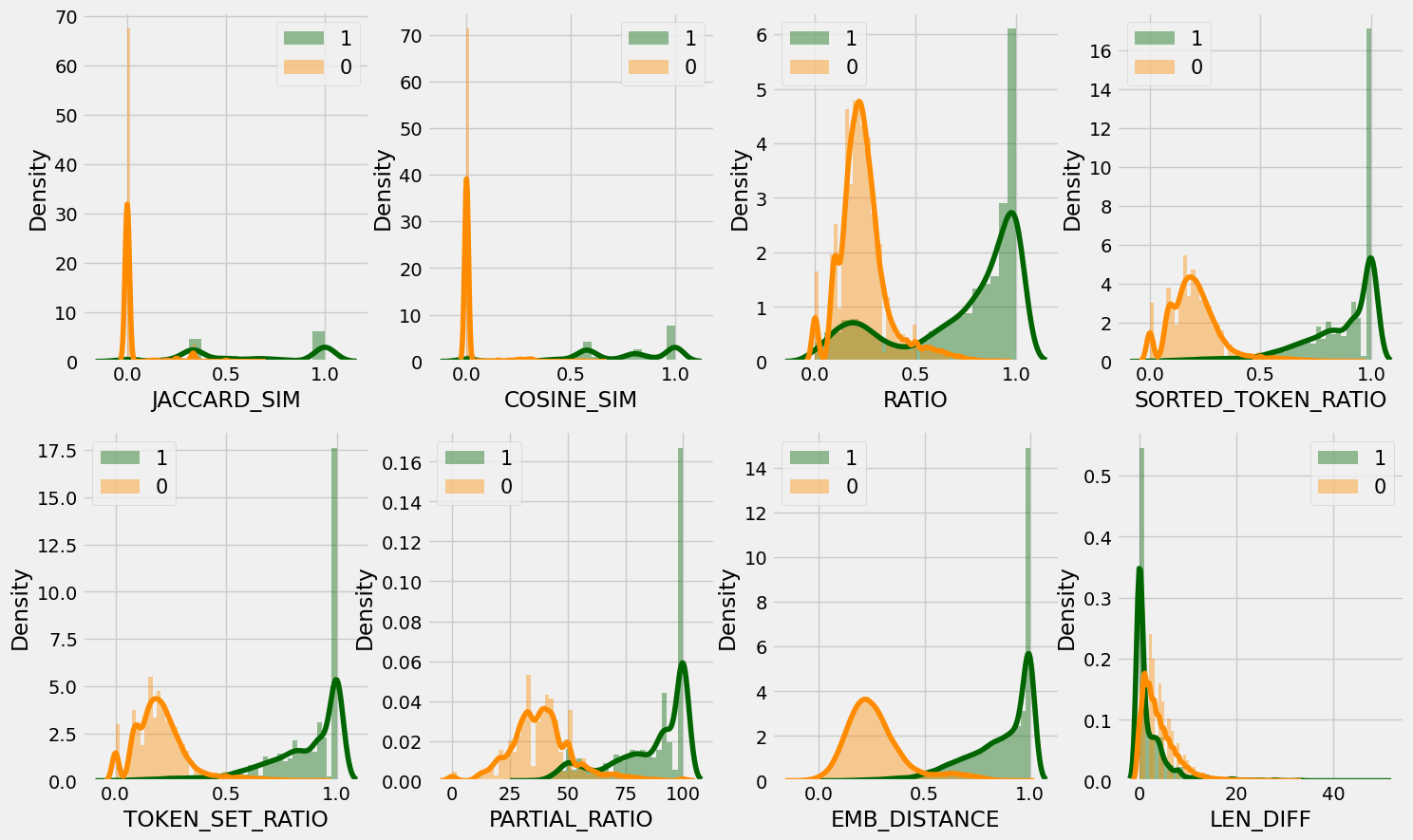
To train the model, I stick to the traditional train-test split of 80/20 on the generated training examples described above. The figure below plots the feature distribution of the training set between the 2 classes “positive” (1) and “negative” (0). As can be seen in the figure, most of the features separate quite well the 2 classes, which indicates the excellent discriminative power of the proposed features.
The model is then trained using the LightGBM package as a binary classifier using some preset optimal hyper-parameters. Comprehensive hyper-parameter tuning can also be performed – refer to the pipeline documentation for instructions on training and hyper-parameter tuning.
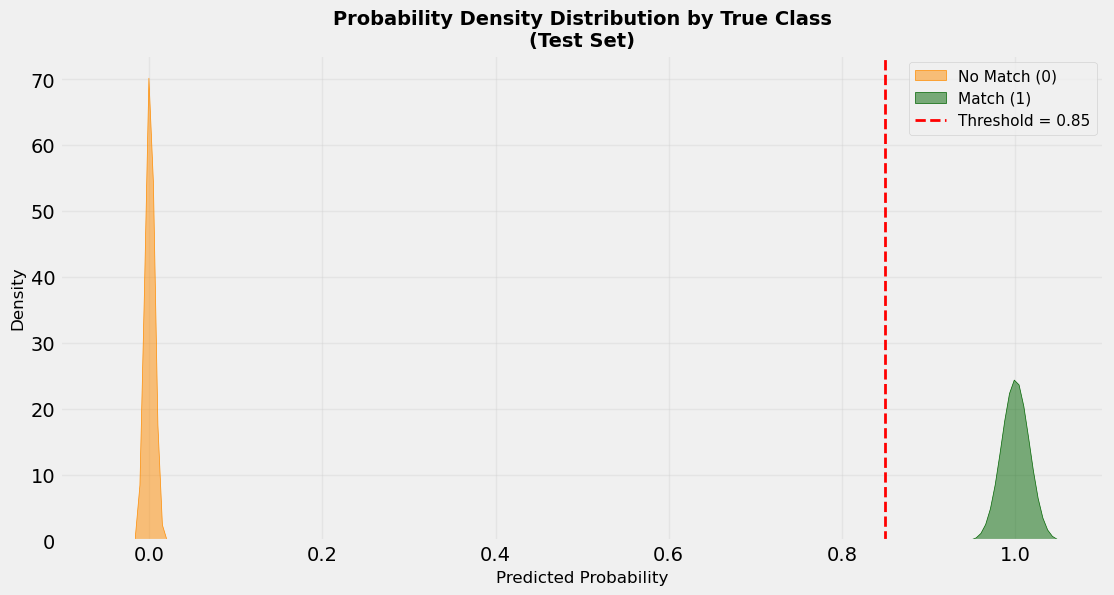
The figure below shows the distribution of the 2 classes in the test set. It shows an obviously clear separation of the 2 classes such that any reasonable probability threshold (say 0.85 as depicted) can easily discriminate them. This might look “too good to be true”, and it’s rightfully so because this is trained and tested using synthetically generated names. Real-world data would be far more complex and “dirtier”, and the realistic curves (distribution of the positive and negative classes) would have some overlap where a deliberate and careful threshold calibration would be meaningful.
The classification results of the test set are shown in the table below. As the table shows, they are quite unrealistically good for the same reasons stated above. It’s also worth mentioning here that the area under the curve (AUC) of the Precision-Recall (PR) curve is about 99.96%.
| Metric | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Class 0 | 0.9977 | 0.9990 | 0.9984 | 7051 |
| Class 1 | 0.9963 | 0.9915 | 0.9939 | 1880 |
| Accuracy | - | - | 0.9974 | 8931 |
| Macro Avg | 0.9970 | 0.9952 | 0.9961 | 8931 |
| Weighted Avg | 0.9974 | 0.9974 | 0.9974 | 8931 |
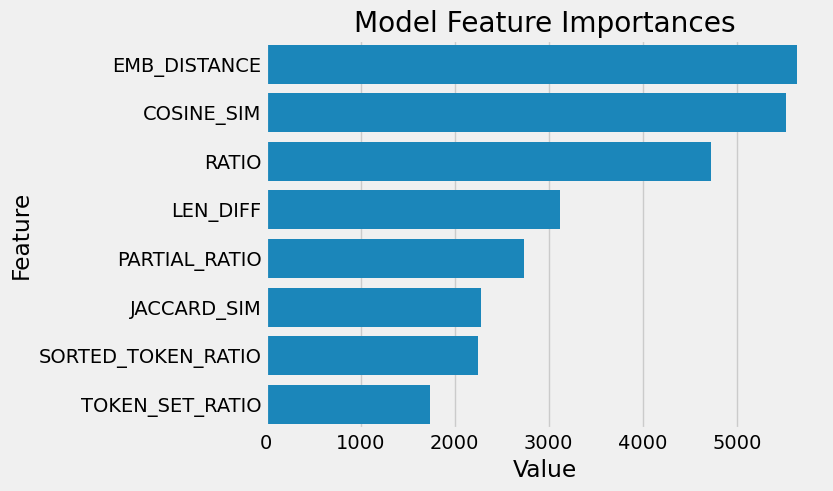
Finally, the figure below shows the feature importance of the trained LightGBM model. It should come as no surprise that the two most importance features are Embedding Distance and (TF-IDF) Cosine Similarity as these two encompass nuances and subtle linguistic similarities in names the most.
API implementation
Last but not least, the package comes with full API implementation using Flask for modular reusability (provided a model has been fully trained and pickled) and adaptability to other applications. Refer to the API documentation for usage instructions. There is also example Python code for calling model inferences using various API endpoints.