 Home
HomeProjects
This page documents all the data science projects that I have worked on since the early undergraduate days, when I was first exposed to data analysis using R, until my current professional endeavor as a data scientist. Projects whose data are non-proprietary are put on my public GitHub repos.
Contents
- AI Agents for Credit Memo Generation
- Anomaly Detection in Transaction Networks
- Property Mapping for Non-hotel Accommodations
- Cash Application: The Multi-match Problem
- Law Enforcement Resource Optimization
- Real-time Dwell Time Prediction Using Passive Wi-Fi Data
- Urban Transportation
- Human Mobility Analytics
- Image Classification
- Social Network Analysis
- Modeling Hospital Length of Stay
AI Agents for Credit Memo Generation
(Jan 2025 – Present)
 Credit risk officers typically spend a significant amount of time on manual work: Processing heterogeneous bank and financial statements, normalizing tables that differ by format and layout, and computing the same financial metrics before drafting a credit memo. This process is slow, error-prone, and fundamentally unscalable – especially when documents arrive as scanned PDFs, spreadsheets, or bespoke bank templates.
Credit risk officers typically spend a significant amount of time on manual work: Processing heterogeneous bank and financial statements, normalizing tables that differ by format and layout, and computing the same financial metrics before drafting a credit memo. This process is slow, error-prone, and fundamentally unscalable – especially when documents arrive as scanned PDFs, spreadsheets, or bespoke bank templates.
An Agentic AI approach fundamentally reinvents this workflow as a coordinated system of specialized agents: One agent detects and reconstructs tabular structures across arbitrary formats, another semantically classifies financial line items (e.g., salary, rental income, dividends, liquid assets, liabilities), while downstream agents compute credit metrics against predefined formulas and compare them to the appraised collateral value. The final agent synthesizes these outputs into a structured, auditable credit memo, transforming raw financial documents into a decision-ready recommendation with traceability at every step.
Anomaly Detection in Transaction Networks
(Jan 2022 – Dec 2023)
 Credit Suisse AG (now part of UBS Group) was a global Swiss private bank. This project seeks to transform the bank’s AML (anti-money laundering) and transaction monitoring capabilities using AI and ML. Specifically, we model transaction data and known client relationships as a knowledge graph and apply entity resolution to resolve ambiguities between nodes in the graph as well as merging and aggregating information of external entities (i.e., non-clients). The entity resolution is a proprietary ML model developed completely in-house. The resolved graph represents an ontology of clients’ transactional relationships, where we apply subgraph mining to detect and extract common money-laundering patterns. Due to potentially large number of such subgraphs extracted (most of which would be false positives), an anomaly detection algorithm is finally used to classify such subgraphs as suspicious or not. AML experts would then follow up to investigate detected suspicious activities.
Credit Suisse AG (now part of UBS Group) was a global Swiss private bank. This project seeks to transform the bank’s AML (anti-money laundering) and transaction monitoring capabilities using AI and ML. Specifically, we model transaction data and known client relationships as a knowledge graph and apply entity resolution to resolve ambiguities between nodes in the graph as well as merging and aggregating information of external entities (i.e., non-clients). The entity resolution is a proprietary ML model developed completely in-house. The resolved graph represents an ontology of clients’ transactional relationships, where we apply subgraph mining to detect and extract common money-laundering patterns. Due to potentially large number of such subgraphs extracted (most of which would be false positives), an anomaly detection algorithm is finally used to classify such subgraphs as suspicious or not. AML experts would then follow up to investigate detected suspicious activities.
This capability significantly improves the efficiency and effectiveness of detecting fraudulent activities in transaction networks by refocusing human expertise on truly meaningful leads.
Property Mapping for Non-hotel Accommodations
(Sept 2019 – Nov 2021)
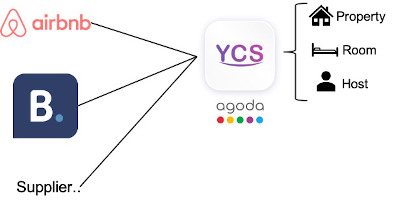 Agoda is a global online travel agency (OTA) for hotels, vacation rentals, flights and airport transfers. Millions of users search for their accommodations and millions of accommodation suppliers list their properties on Agoda. Non-hotel accommodations (NHA), pioneered by Airbnb, have experienced steady growth in recent years due to unique experiences that they offer to travelers. The property mapping problem is to match duplicate listings across different suppliers that Agoda can pull from in order to enhance user experience on the platform. This can range from fetching contents from other NHA providers to aggregating inventories sister suppliers (such as Booking.com).
Agoda is a global online travel agency (OTA) for hotels, vacation rentals, flights and airport transfers. Millions of users search for their accommodations and millions of accommodation suppliers list their properties on Agoda. Non-hotel accommodations (NHA), pioneered by Airbnb, have experienced steady growth in recent years due to unique experiences that they offer to travelers. The property mapping problem is to match duplicate listings across different suppliers that Agoda can pull from in order to enhance user experience on the platform. This can range from fetching contents from other NHA providers to aggregating inventories sister suppliers (such as Booking.com).
In the context of NHA, the problem is further challenging due to rich unstructured data that hosts use to describe and list their properties. These unstructured data include free texts (that may come in the host’s native language) and images. This is in contrast to traditional hotel mapping, where most hotels have standardized structured data (e.g., fixed room types). To this end, an efficient machine learning pipeline is proposed to process both structured and unstructured features of the properties using a combination of traditional machine learning and advanced deep learning. The pipeline processes millions of pairs of properties daily with high precision and recall.
Cash Application: The Multi-match Problem
(Jul 2017 – Dec 2018)
 The main task cash application is to match the incoming bank statements to the correct set of open invoices (called open ‘receivables’) issued by a business to its customers. This process typically involves first applying the bank statement to the correct customer’s account, and then to the correct outstanding invoice(s) in the account. A single match arises when a bank statement is matched to exactly one invoice. However, customer often conveniently makes a lump sum payment for a set of invoices. This further complicates the matching process because retrieving those invoices whose sum of amounts match (as closely as possible) that of the bank statement is an instance of the well-known subset sum problem. This is called the multi-match problem of cash application. In short, it is the problem of matching one bank statement to a correct set of open invoices.
The main task cash application is to match the incoming bank statements to the correct set of open invoices (called open ‘receivables’) issued by a business to its customers. This process typically involves first applying the bank statement to the correct customer’s account, and then to the correct outstanding invoice(s) in the account. A single match arises when a bank statement is matched to exactly one invoice. However, customer often conveniently makes a lump sum payment for a set of invoices. This further complicates the matching process because retrieving those invoices whose sum of amounts match (as closely as possible) that of the bank statement is an instance of the well-known subset sum problem. This is called the multi-match problem of cash application. In short, it is the problem of matching one bank statement to a correct set of open invoices.
In the (US) patents below, we propose a novel and scalable solution to the multi-match problem based on concepts and techniques in graph theory and deep learning.
- Truc Viet Le, Sean Saito, Rajalingappaa Shanmugamani and Chaitanya Joshi. A Graphical Approach to the Multi-match Problem. Published June 11, 2020. [URL]
- Sean Saito, Truc Viet Le, Rajalingappaa Shanmugamani and Chaitanya Joshi. Representing Sets of Entities for Matching Problems. Published June 04, 2020. [URL]
- Rajalingappaa Shanmugamani, Chaitanya Joshi, Rajesh Arumugam, Sean Saito and Truc Viet Le. Utilizing Embeddings for Efficient Matching of Entities. Published June 18, 2020. [URL]
Law Enforcement Resource Optimization
(Aug 2016 – Jun 2017)
 In today’s world of heightened security concerns, there has been an increased pressure on law enforcement agencies around the world to deploy resources as efficiently as possible to respond to crimes and emergent incidents. Such pressure often results in manpower crunches on law enforcement agencies trying meet the rising demands in large and densely populated urban areas. With the help of big spatiotemporal data that provides fine-grained details of crime incidents, it is now possible to design adaptive and data-driven staffing models that optimize the allocation of resources and improve responses to incidents. In this project, we are provided with multi-year fine-grained crime data from a national law enforcement agency in order to provide optimal data-driven solutions to the agency.
In today’s world of heightened security concerns, there has been an increased pressure on law enforcement agencies around the world to deploy resources as efficiently as possible to respond to crimes and emergent incidents. Such pressure often results in manpower crunches on law enforcement agencies trying meet the rising demands in large and densely populated urban areas. With the help of big spatiotemporal data that provides fine-grained details of crime incidents, it is now possible to design adaptive and data-driven staffing models that optimize the allocation of resources and improve responses to incidents. In this project, we are provided with multi-year fine-grained crime data from a national law enforcement agency in order to provide optimal data-driven solutions to the agency.
- Jonathan Chase, Jiali Du, Na Fu, Truc Viet Le and Hoong Chuin Lau. Law Enforcement Resource Optimization with Response Time Guarantees. IEEE SSCI 2017.
Real-time Dwell Time Prediction Using Passive Wi-Fi Data
(May – Jul 2016)
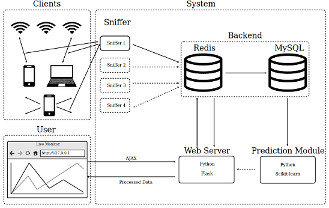 The proliferation of wireless technologies in today’s everyday life is one of the key drivers of the Internet of Things (IoT). In addition, the vast penetration of wireless devices gives rise to a secondary functionality as a means of tracking and localization. In order to connect to known Wi-Fi networks, mobile devices have to scan and broadcast probe requests on all available channels, which can be captured and analyzed in a non-intrusive manner. Thus, one of the key applications of this feature is the ability to track and analyze human behaviors in real-time directly from the patterns observed from their devices. In this project, we develop such a system to obtain these Wi-Fi signatures in a completely passive manner coupled with adaptive machine learning techniques to predict in real-time the expected dwell time of the device owners at a specific location. We empirically evaluate the proposed system using real-world Wi-Fi data collected at retail locations that have diverse human mobility patterns. The system was mostly implemented in Python using scikit-learn and Wireshark packages.
The proliferation of wireless technologies in today’s everyday life is one of the key drivers of the Internet of Things (IoT). In addition, the vast penetration of wireless devices gives rise to a secondary functionality as a means of tracking and localization. In order to connect to known Wi-Fi networks, mobile devices have to scan and broadcast probe requests on all available channels, which can be captured and analyzed in a non-intrusive manner. Thus, one of the key applications of this feature is the ability to track and analyze human behaviors in real-time directly from the patterns observed from their devices. In this project, we develop such a system to obtain these Wi-Fi signatures in a completely passive manner coupled with adaptive machine learning techniques to predict in real-time the expected dwell time of the device owners at a specific location. We empirically evaluate the proposed system using real-world Wi-Fi data collected at retail locations that have diverse human mobility patterns. The system was mostly implemented in Python using scikit-learn and Wireshark packages.
- Truc Viet Le, Baoyang Song and Laura Wynter. Real-time Prediction of Length of Stay Using Passive Wi-Fi Sensing. IEEE ICC 2017, Internet of Things (IoT) Track. [Get PDF] [Slides]
Urban Transportation
(Jun 2015 – Apr 2016)
Self-driving Using Reinforcement Learning
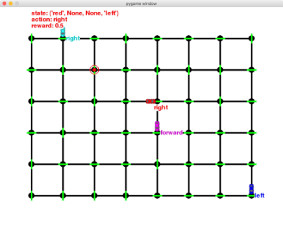 Reinforcement learning is at the heart of modern AI techniques. It is the underpinning of recent breakthroughs such as AlphaGo and driverless cars. In this project, I apply the main ideas of reinforcement learning called Q-learning to an interesting hypothetical application called Smartcab. Smartcab is a simplistic simulation of a self-driving car from the not-so-distant future that ferries people from one location to another. This application demonstrates how Q-learning can be used to train smart smartcabs to desired self-driving behaviors through trials and errors in a well-defined environment and reward structure. The application is developed using Python and the Pygame framework.
Reinforcement learning is at the heart of modern AI techniques. It is the underpinning of recent breakthroughs such as AlphaGo and driverless cars. In this project, I apply the main ideas of reinforcement learning called Q-learning to an interesting hypothetical application called Smartcab. Smartcab is a simplistic simulation of a self-driving car from the not-so-distant future that ferries people from one location to another. This application demonstrates how Q-learning can be used to train smart smartcabs to desired self-driving behaviors through trials and errors in a well-defined environment and reward structure. The application is developed using Python and the Pygame framework.
This project was inspired from an original Udacity coursework. [Watch video] [Slides] [Source code]
Fine-grained Traffic Speed Prediction Using Big Data
 Traffic speed is a key indicator of the efficiency of an urban transportation system. This project addresses the problem of efficient and fine-grained speed prediction using big traffic data obtained from traffic sensors. Gaussian processes (GPs) have been used to model various traffic phenomena; however, GPs do not scale with big data due to their cubic time complexity. We address such efficiency issues by proposing local GPs to learn from and make predictions for correlated subsets of data. The main idea is to quickly group speed variables in both spatial and temporal dimensions into a finite number of clusters, so that future and unobserved traffic speed queries can be heuristically mapped to one of such clusters. A local GP corresponding to that cluster can then be trained on the fly to make predictions in real-time. We call this localization, which is done using non-negative matrix factorization. We additionally leverage on the expressiveness of GP kernel functions to model the road network topology and incorporate side information. Extensive experiments using real-world traffic data show that our proposed method significantly improve both the runtime and prediction performances.
Traffic speed is a key indicator of the efficiency of an urban transportation system. This project addresses the problem of efficient and fine-grained speed prediction using big traffic data obtained from traffic sensors. Gaussian processes (GPs) have been used to model various traffic phenomena; however, GPs do not scale with big data due to their cubic time complexity. We address such efficiency issues by proposing local GPs to learn from and make predictions for correlated subsets of data. The main idea is to quickly group speed variables in both spatial and temporal dimensions into a finite number of clusters, so that future and unobserved traffic speed queries can be heuristically mapped to one of such clusters. A local GP corresponding to that cluster can then be trained on the fly to make predictions in real-time. We call this localization, which is done using non-negative matrix factorization. We additionally leverage on the expressiveness of GP kernel functions to model the road network topology and incorporate side information. Extensive experiments using real-world traffic data show that our proposed method significantly improve both the runtime and prediction performances.
- Truc Viet Le, Richard J. Oentaryo, Siyuan Liu and Hoong Chuin Lau. Local Gaussian Processes for Efficient Fine-Grained Traffic Speed Prediction. IEEE Transactions on Big Data (2017). [Read more]
Human Mobility Analytics
(Jan 2013 – May 2015)
We collected big mobility data of visitors to the resort island of Sentosa in Singapore. The data was collected through bundle packages such as Day Pass and associated RFID-enabled devices. We propose various analytical frameworks to model and predict the visitors’ trajectories. Our methods include revealed preference analysis and reinforcement learning. Applications include designing bundle packages that optimize visitors’ experiences and theme park’s revenue, and recommending optimal plans to the visitors to avoid congestions and reduce queue lengths.
Trajectory Prediction
![]() We consider the problem of trajectory prediction, where a trajectory is an ordered sequence of location visits and corresponding timestamps. The problem arises when an agent makes sequential decisions to visit a set of spatial POIs. Each location bears a stochastic utility and the agent has a limited budget to spend. Given the agent’s observed partial trajectory, our goal is to predict the agent’s remaining trajectory. We propose a solution framework to the problem that incorporates both the stochastic utility of each location and the agent’s budget constraint. We first cluster the agents into “types”. Each agent’s trajectory is then transformed into a discrete-state sequence representation. We then use reinforcement learning (RL) to model the underlying decision processes and inverse RL to learn the utility distributions of the locations. We finally propose two decision models to make predictions: one is based on long-term optimal planning of RL and another uses myopic heuristics. We apply the framework to predict real-world human trajectories and are able to explain the underlying processes of the observed actions.
We consider the problem of trajectory prediction, where a trajectory is an ordered sequence of location visits and corresponding timestamps. The problem arises when an agent makes sequential decisions to visit a set of spatial POIs. Each location bears a stochastic utility and the agent has a limited budget to spend. Given the agent’s observed partial trajectory, our goal is to predict the agent’s remaining trajectory. We propose a solution framework to the problem that incorporates both the stochastic utility of each location and the agent’s budget constraint. We first cluster the agents into “types”. Each agent’s trajectory is then transformed into a discrete-state sequence representation. We then use reinforcement learning (RL) to model the underlying decision processes and inverse RL to learn the utility distributions of the locations. We finally propose two decision models to make predictions: one is based on long-term optimal planning of RL and another uses myopic heuristics. We apply the framework to predict real-world human trajectories and are able to explain the underlying processes of the observed actions.
- Truc Viet Le, Siyuan Liu and Hoong Chuin Lau. A Reinforcement Learning Framework for Trajectory Prediction Under Uncertainty and Budget Constraint. ECAI 2016. [Get PDF] [Slides]
Spatial Choice Prediction
 We propose the problem of predicting a bundle of goods, where the goods considered is a set of spatial locations that an agent wishes to visit. This typically arises in the tourism setting where attractions can often be bundled and sold as a package. We look at the problem from an economic point of view. That is, we view an agent’s past trajectories as revealed preference (RP) data, where the choice of locations is a solution to an optimization problem according to some unknown utility function and subject to the prevailing prices and budget constraint. We approximate the prices and budget constraint as the time costs to visit the chosen locations. We leverage on a recent line of work that has established efficient algorithms to recover utility functions from RP data and adapt it to our original setting. We experiment with real-world trajectories and our predictions show significantly improved accuracies compared with the baseline methods.
We propose the problem of predicting a bundle of goods, where the goods considered is a set of spatial locations that an agent wishes to visit. This typically arises in the tourism setting where attractions can often be bundled and sold as a package. We look at the problem from an economic point of view. That is, we view an agent’s past trajectories as revealed preference (RP) data, where the choice of locations is a solution to an optimization problem according to some unknown utility function and subject to the prevailing prices and budget constraint. We approximate the prices and budget constraint as the time costs to visit the chosen locations. We leverage on a recent line of work that has established efficient algorithms to recover utility functions from RP data and adapt it to our original setting. We experiment with real-world trajectories and our predictions show significantly improved accuracies compared with the baseline methods.
- Truc Viet Le, Siyuan Liu, Hoong Chuin Lau and Ramayya Krishnan. Predicting Bundles of Spatial Locations from Learning Revealed Preference Data. AAMAS 2015. [Get PDF] [Slides]
Image Classification
(Aug – Dec 2014)
 We perform the image classification task on the CIFAR-10 dataset, where each image belongs to one of the 10 distinct classes. The classes are mutually exclusive and are mostly objects and animals. The images are small, of uniform size and shape, and are RGB colored. We implement an image preprocessing framework to learn and extract the salient features of the training images. With preprocessing, we see a considerable improvement of more than 15% from the baseline (i.e., without preprocessing). We also experiment with a variety of classifiers on the preprocessed images and find out that a linear SVM performs the best. We finally experiment with ensemble learning by combining a SVM with a multinomial logistic regression, which marginally improves on the linear SVM at a high complexity.
We perform the image classification task on the CIFAR-10 dataset, where each image belongs to one of the 10 distinct classes. The classes are mutually exclusive and are mostly objects and animals. The images are small, of uniform size and shape, and are RGB colored. We implement an image preprocessing framework to learn and extract the salient features of the training images. With preprocessing, we see a considerable improvement of more than 15% from the baseline (i.e., without preprocessing). We also experiment with a variety of classifiers on the preprocessed images and find out that a linear SVM performs the best. We finally experiment with ensemble learning by combining a SVM with a multinomial logistic regression, which marginally improves on the linear SVM at a high complexity.
This was a coursework project of 10-601 at CMU. [Get PDF] [Source code]
Social Network Analysis
(Jan – May 2013)
 We collected data from Stack Overflow for the duration of two years (2011–2012) and constructed a large network of users (i.e., each node is a unique user) that represents the relationships between ‘askers’ and ‘answerers’ on the platform. We call that the network of expertise. We analyzed the network structure and reciprocal patterns among its users. We used network centrality measures, principal component analysis, and linear regression to describe and characterize what makes an expert user in the constructed graph.
We collected data from Stack Overflow for the duration of two years (2011–2012) and constructed a large network of users (i.e., each node is a unique user) that represents the relationships between ‘askers’ and ‘answerers’ on the platform. We call that the network of expertise. We analyzed the network structure and reciprocal patterns among its users. We used network centrality measures, principal component analysis, and linear regression to describe and characterize what makes an expert user in the constructed graph.
- Truc Viet Le and Minh Thap Nguyen. An Empirical Analysis of a Network of Expertise. ASONAM 2013. [Read more]
Modeling Hospital Length of Stay
(Jan 2008 – May 2009)
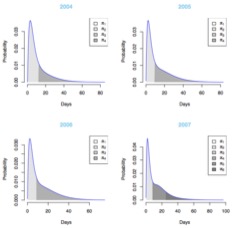 We collected a large-scale dataset over four years (2004–2007) of stroke patients admitted to the Singapore General Hospital. The dataset contained the typically long-tailed distribution of hospital length of stay (LOS) as the primary health-care outcome, and other (time-dependent) explanatory variables. We used survival models to analyze the risk factors affecting the patients’ LOS and proposed Coxian phase-type distributions to model the distribution of LOS and analyze its trend over time.
We collected a large-scale dataset over four years (2004–2007) of stroke patients admitted to the Singapore General Hospital. The dataset contained the typically long-tailed distribution of hospital length of stay (LOS) as the primary health-care outcome, and other (time-dependent) explanatory variables. We used survival models to analyze the risk factors affecting the patients’ LOS and proposed Coxian phase-type distributions to model the distribution of LOS and analyze its trend over time.
This was the final year project of my bachelor’s degree.
-
Truc Viet Le, Chee Keong Kwoh, Kheng Hock Lee and Eng Soon Teo. Trend Analysis of Length of Stay Data via Phase-type Models. International Journal of Knowledge Discovery in Bioinformatics (IJKDB). [Read more]
-
Chee Keong Kwoh, Kheng Hock Lee and Truc Viet Le. Using Survival Models to Analyze the Effects of Social Attributes on Length of Stay of Stroke Patients. ICBPE 2009. [Read more]